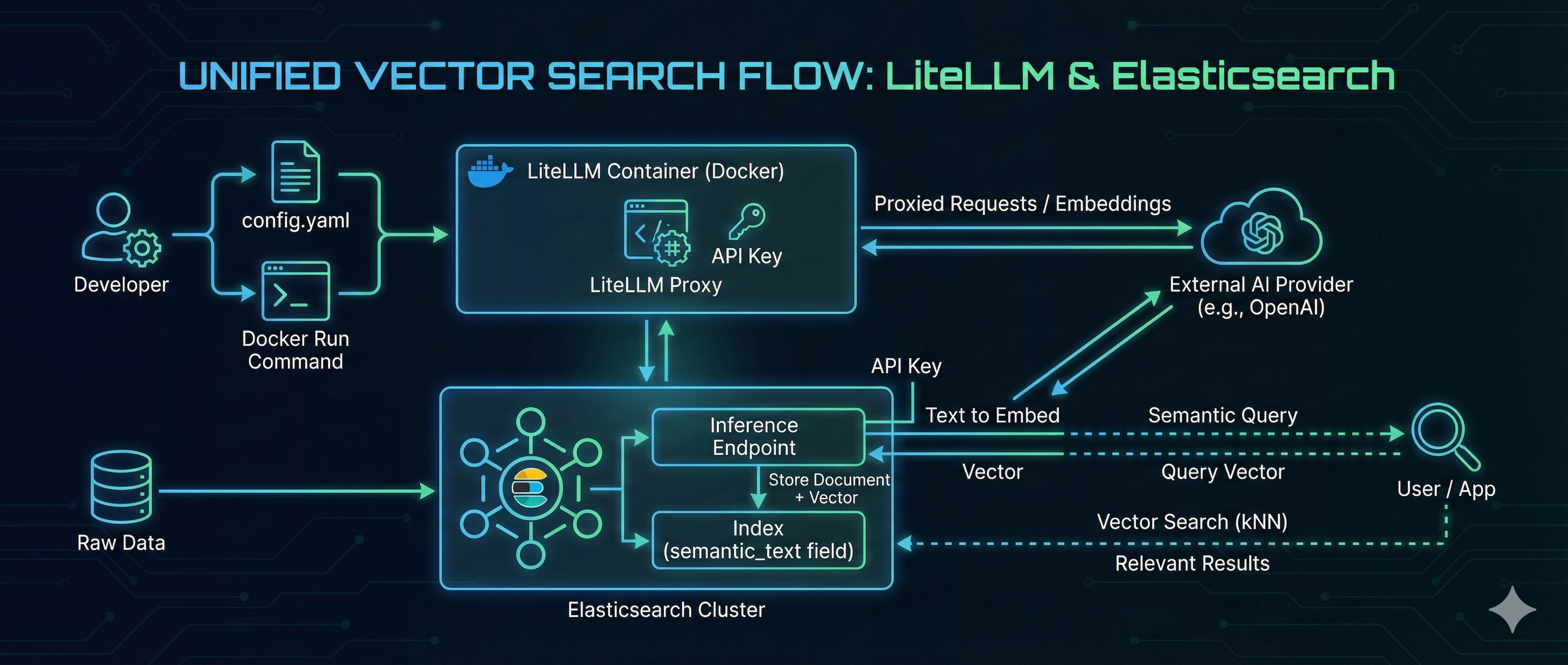
Streamlining Vector Search with private model: Unifying Embedding Models with LiteLLM and Elasticsearch
In the rapidly evolving landscape of AI, managing the “plumbing” between your embedding models and your search engine is often a challenge. Developers frequently struggle with switching providers, managing API keys, and maintaining consistent API specifications. LiteLLM solves the model management problem by acting as a universal proxy, while Elasticsearch delivers high-performance Vector Search. By combining them, you can build a search architecture that is both flexible and powerful. In this guide, we will walk through hosting an OpenAI-compatible embedding model using LiteLLM on Docker and consuming it directly from Elasticsearch to perform seamless vector search. ...