Introduction
In this blog, we will try to understand how “Search as you type” works and Quickly setup one demo using some sample data. You must have seen various websites like eCommerce, food apps, etc. where you just start typing & simultaneously relevant options start displaying as suggestions and autocomplete. We will try to achieve somewhat the same feature. Search as you type Elasticsearch gives this specific mapping type which you can simply set to a specific field where you want to perform this kind of search.
Why search_as_you_type?
No need to think about what kind of functionality like analyzer, tokenizer, etc. you have to apply to achieve this. It automatically handles everything in the backend by producing necessary terms on which you can query efficiently.
You can simply create mapping like the below example:
Create Index
PUT products
{
"mappings": {
"properties": {
"description": {
"type": "search_as_you_type"
}
}
}
}
Insert sample data
POST products/_doc/
{
"description": "best jogging shoes for men"
}
How is data indexed ?
search_as_you_type mapping creates 4 types of fields in the backend.
Field 1: description
It will produce the terms according to the default analyzer if no analyzer is defined i.e. standard analyzer.
[
"best",
"jogging",
"shoes",
"for",
"men"
]
Field 2: description._2gram
This will use a shingle token filter and produce the terms with shingle size 2. This means a shingle token filter produces the token by concatenating the adjacent token. You can find more here.
This operation will perform on all the terms which are created on the description field and it will produce the below terms.
[
"best jogging",
"jogging shoes",
"shoes for",
"for men"
]
Field 3: description._3gram
This will also use a shingle token filter and produce the terms with shingle size 3. This means it will concatenate 3 adjacent tokens like below.
[
"best jogging shoes",
"jogging shoes for",
"shoes for men"
]
Field 4: description._index_prefix
This will apply an edge n gram token filter on the field description._3gram which means it will split terms (words) of description._3gram to a small substring that will start from the edge.
You can have a look at the terms below.
[
"b",
"be",
"bes",
"best",
"best ",
"best j",
"best jo",
"best jog",
"best jogg",
"best joggi",
"best joggin",
"best jogging",
"best jogging ",
"best jogging s",
"best jogging sh",
"best jogging sho",
"best jogging shoe",
"best jogging shoes",
"j",
"jo",
"jog",
"jogg",
"joggi",
"joggin",
"jogging",
"jogging ",
"jogging s",
"jogging sh",
"jogging sho",
"jogging shoe",
"jogging shoes",
"jogging shoes ",
"jogging shoes f",
"jogging shoes fo",
"jogging shoes for",
"s",
"sh",
"sho",
"shoe",
"shoes",
"shoes ",
"shoes f",
"shoes fo",
"shoes for",
"shoes for ",
"shoes for m",
"shoes for me",
"shoes for men",
"f",
"fo",
"for",
"for ",
"for m",
"for me",
"for men",
"for men ",
"m",
"me",
"men",
"men ",
"men "
]
As you noticed the token limit is up to 3 words only because description._3gram has generated 3 word tokens only.
Search Query
multi_match
We will use a multi_match query here. Because we want to look up on each subfield for a perfect match.
GET products/_search
{
"query": {
"multi_match": {
"query": "jogging",
"fields": [
"description",
"description._2gram",
"description._3gram"
]
}
}
}
The above query is going to search the term "jogging" on all 3 subfields which are specified in fields[].
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "products",
"_id" : "TSNNiX8BYh0NLleBiu4u",
"_score" : 0.2876821,
"_source" : {
"description" : "best jogging shoes for men"
}
}
]
}
}
Lets try with any substring (jog).
GET products/_search
{
"query": {
"multi_match": {
"query": "jog",
"fields": [
"description",
"description._2gram",
"description._3gram"
]
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
The result is empty. Because there is no term created with the name jog if you closely look at the above generated tokens on respective fields.
To solve this we need to use the bool_prefix query.
bool_prefix analyze the input and constructs the bool query from the terms. But it puts the last term in the prefix query. For example, input is given as men jogging s, So it will produce terms like ["men","jogging","s"] but it will always perform a prefix query on the last term which is "s". So documents will return where terms will match with "men" or "jogging" or any term which is starting with "s".
Below is the query which will give you the desired output.
GET products/_search
{
"query": {
"multi_match": {
"query": "jog",
"type": "bool_prefix",
"fields": [
"description",
"description._2gram",
"description._3gram"
]
}
}
}
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "products",
"_id" : "TSNNiX8BYh0NLleBiu4u",
"_score" : 1.0,
"_source" : {
"description" : "best jogging shoes for men"
}
}
]
}
}
Here when we make a prefix query on the root field (description) or any subfields, It will rewrite the query as a term query on description._index_prefix field.
This matches more efficiently because prefixes up to 3 words are already created as the terms as shown in the above.
Note: This query will search for terms irrespective of order. For example, if we search for
jogging men, This will also give the result because it will search for both the termsjoggingormen. In most of the cases this query (multi_match + bool_prefix) is recommended because the end user can search for any string likeshoesorshoes for menorjogging shoesetc.
What if you want to search with strict prefix order?
You can use match_phrase_prefix, It will strictly match input from prefix in the same order only. So input like “men best” won’t return anything. Whereas you will get results with the previous one.
GET products/_search
{
"query": {
"match_phrase_prefix": {
"description": "best jogging s"
}
}
}
It will return documents where the term’s prefix will be matched with “best jogging s”. Sometimes it can provide confusing results. You can check more about match_phrase_prefix.
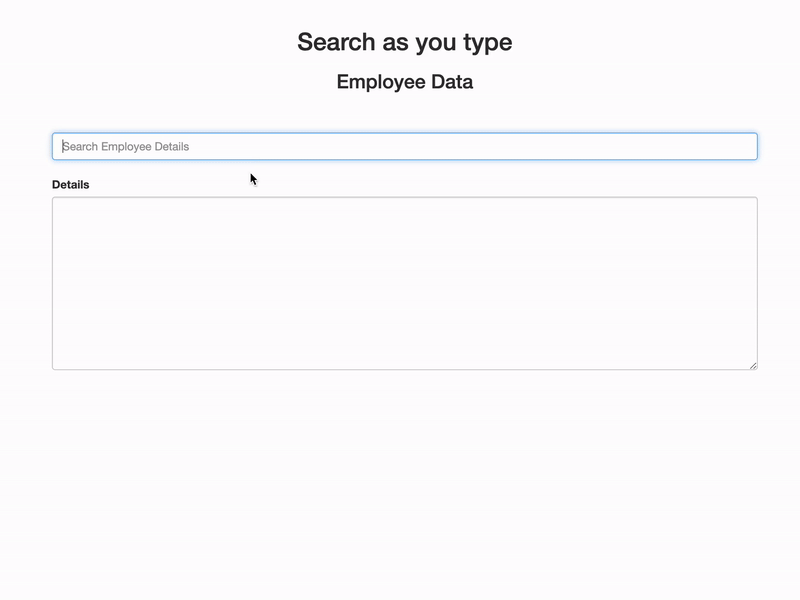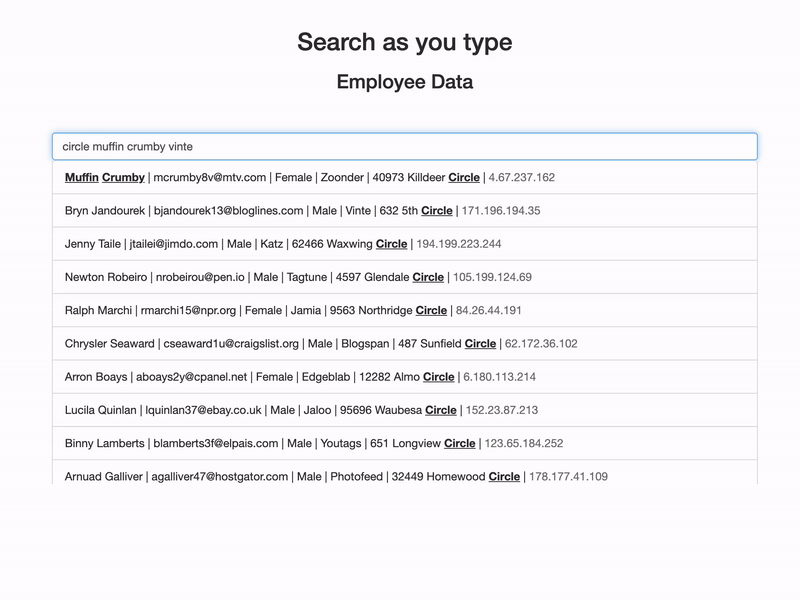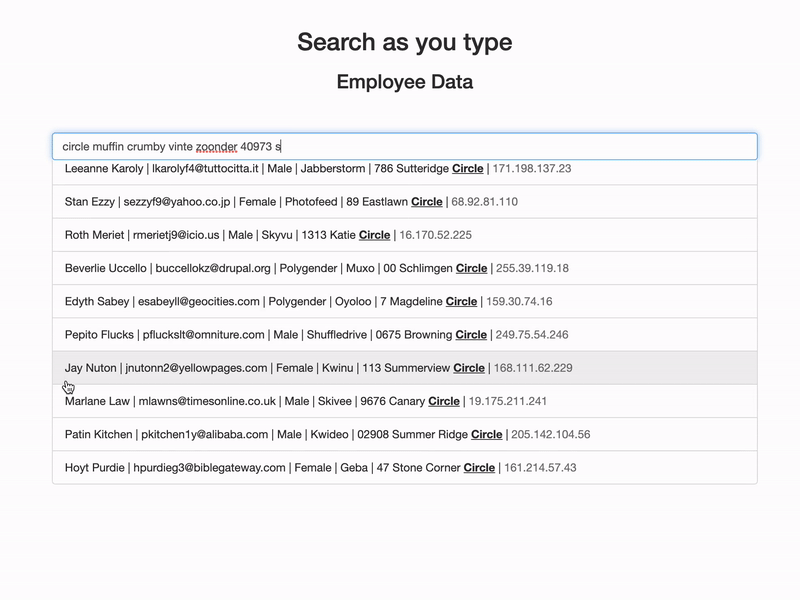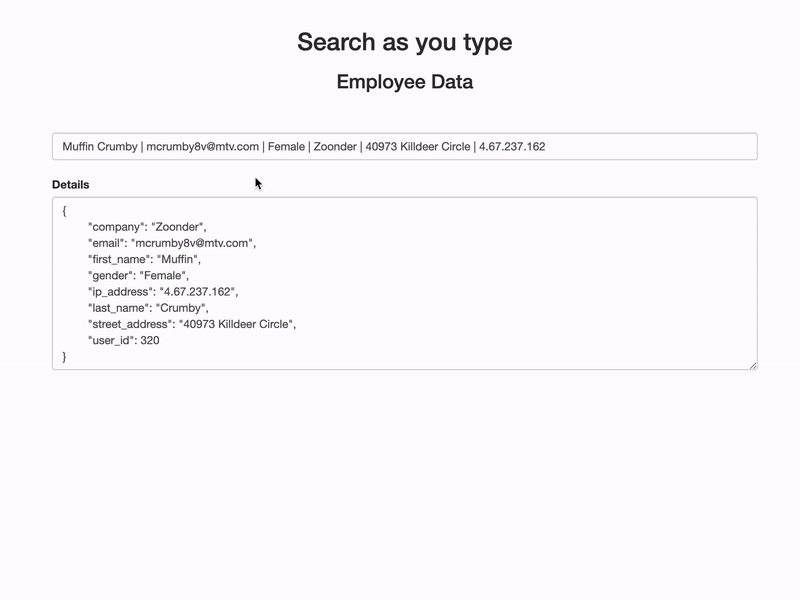
Demo
Let’s take a practical experience of how it is going to work.
Search As You Type (Elasticsearch)
Demo code and sample employees data to implement the “Search as you type” feature on elasticsearch.
Written the middleware API in python using flask. Used JQuery for javascript operations.
Installation
Assuming you have successfully installed Elasticsearch and Kibana on your machine and it is working perfectly. Kindly refer respective installation document.
OR
You can run Elasticsearch on the cloud with a few clicks.
Install Python3 & pip3
- Refer Document to install
python3&pip3on your system. - Install
flask
pip3 install flask
- Install
elasticsearchpackage
pip3 install elasticsearch
git Clone
git clone https://github.com/ashishtiwari1993/search_as_you_type.git
cd search_as_you_type
Create Index and load data
Make sure Elasticsearch and kibana are up and running fine on your machine.
Create Index
PUT /sayt?pretty
{
"mappings": {
"properties": {
"first_name": {
"type": "search_as_you_type"
},
"last_name": {
"type": "search_as_you_type"
},
"street_address": {
"type": "search_as_you_type"
},
"company": {
"type": "search_as_you_type"
},
"email": {
"type": "search_as_you_type"
}
}
}
}
Load sample data
Sample data.json file is given which need to load with the help of bulk API.
curl -s -H "Content-Type: application/x-ndjson" -XPOST "localhost:9200/_bulk" --data-binary "@data.json"
Do not forget to change the elasticsearch’s endpoint.
Run api.py & test
Open api.py and change elasticsearch endpoint accordingly.
es = Elasticsearch("http://localhost:9200")
Start API Server
python3 api.py
This will start the API service on port 5001.
Open index.html on your browser.