👋 Hi, I’m Ashish
🇮🇳 From India
🧑💼 Principal Solutions Architect - Search Specialist, Elastic
👀 Developer, Search Engineer (latest interest - Generative AI, vector databases, RAG, agents …)
🧑🤝🧑 Community lover, Speaker, OSS
👋 Hi, I’m Ashish
🇮🇳 From India
🧑💼 Principal Solutions Architect - Search Specialist, Elastic
👀 Developer, Search Engineer (latest interest - Generative AI, vector databases, RAG, agents …)
🧑🤝🧑 Community lover, Speaker, OSS
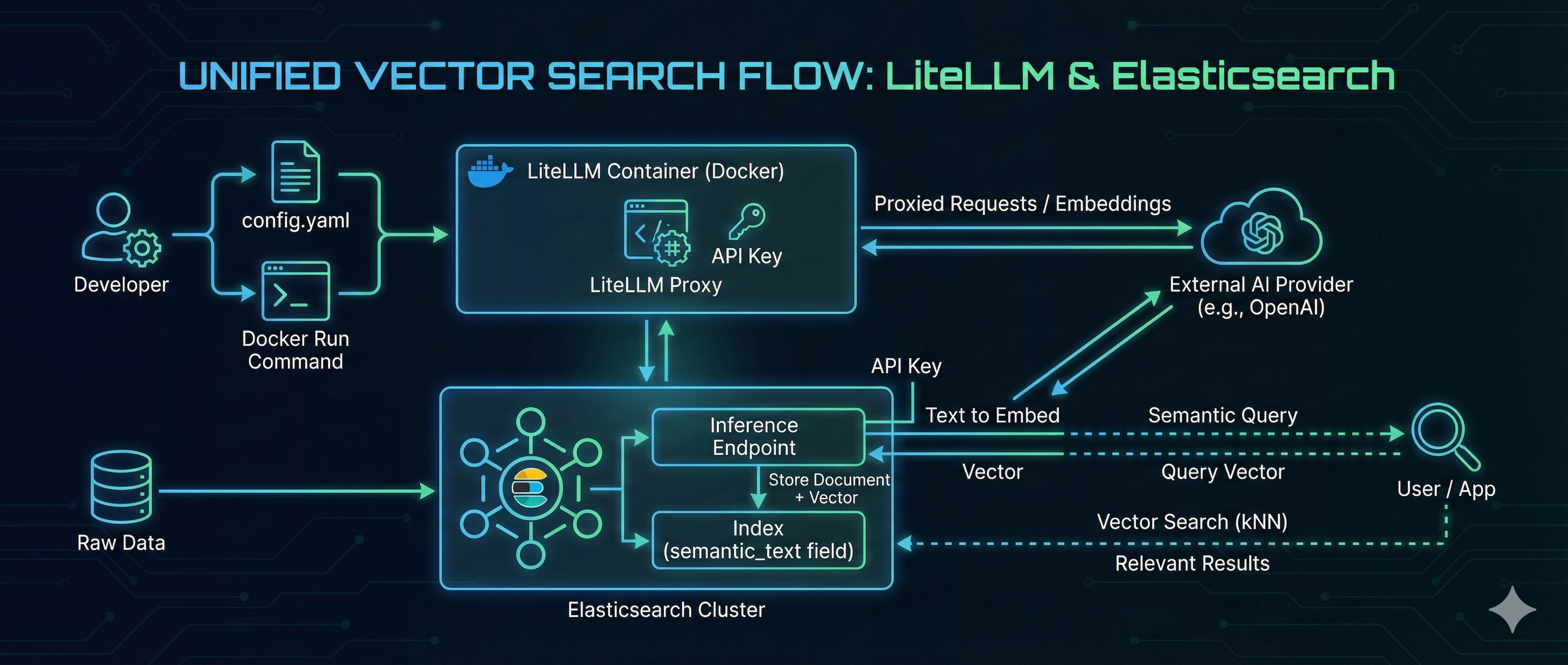
In the rapidly evolving landscape of AI, managing the “plumbing” between your embedding models and your search engine is often a challenge. Developers frequently struggle with switching providers, managing API keys, and maintaining consistent API specifications. LiteLLM solves the model management problem by acting as a universal proxy, while Elasticsearch delivers high-performance Vector Search. By combining them, you can build a search architecture that is both flexible and powerful. In this guide, we will walk through hosting an OpenAI-compatible embedding model using LiteLLM on Docker and consuming it directly from Elasticsearch to perform seamless vector search. ...
Hybrid Search Done Right: Stop Calling Metadata Filters “Hybrid” Everyone’s talking about hybrid search right now. But here’s the uncomfortable truth: 👉 Just because you glued vector search onto your database and added metadata filters doesn’t mean you’ve built true hybrid search. That’s like duct-taping a spoiler on a hatchback and calling it a race car. 🚗💨 Hybrid search is more than just “keyword + vector + filter.” It’s about field-level design, reranking, scoring, and scale. ...

🎤 Talk Summary: No-Code RAG Chatbot with PHP, LLMs & Elasticsearch Speaker: Ashish Diwali (Senior Developer Advocate, Elastic) 🔑 Introduction Topic: Integrating Generative AI (LLMs) with PHP. Goal: Show how to build chat assistants, semantic search, and vector search without heavy ML expertise. Demo focus: Using Elasticsearch + PHP + LLM (LLaMA 3.1). 🧩 Core Concepts 1. Prompt Engineering LLMs generate responses based on prompts → predicting next words. Techniques: Zero-shot inference → direct classification or tagging. One-shot inference → provide one example in the prompt. Few-shot inference → multiple examples → useful for structured outputs (SQL, JSON, XML). Iteration + context = In-context learning (ICL). 2. LLM Limitations ❌ Hallucinations (wrong answers). ❌ Complex to build/train from scratch. ❌ No real-time / private data access. ❌ Privacy & security concerns (especially in banking, public sector). 3. RAG (Retrieval-Augmented Generation) Solution to limitations. Workflow: User query → hits database/vector DB (e.g., Elasticsearch). Retrieve top 5–10 relevant docs. Pass as context window → LLM generates accurate answer. Benefits: Grounded responses. Works with private data. Avoids retraining large models. 🔍 Semantic & Vector Search Semantic Search: Understands meaning, not just keywords. Example: “best city” ↔ “beautiful city.” Vector Search: Text, images, and audio converted into embeddings (arrays of floats). Enables image search, recommendation systems, music search (via humming). Similarity algorithms: cosine similarity, dot product, nearest neighbors. 🛠️ Tools & Demo Elephant Library (PHP) Open-source PHP library for GenAI apps. Supports: LLMs: OpenAI, Mistral, Anthropic, LLaMA. Vector DBs: Elasticsearch, Pinecone, Chroma, etc. Features: document chunking, embedding generation, semantic retrieval, Q&A (RAG). Demo Flow Ingestion: ...

🚀 No-Code Chatbot with Elasticsearch + AWS Bedrock (Talk Summary) Speaker: Ashish (Senior Developer Advocate, Elastic) Event: AWS Community Day Mumbai 2024 🔑 Why Search Still Matters with LLMs LLMs (like ChatGPT) are powerful but face: ❌ Hallucinations 💰 High cost per query 🔒 No access to private / real-time data ✅ Search grounds LLMs in reliable, domain-specific info. ⚡ Elasticsearch Capabilities Traditional keyword search + modern vector search. Real-world use cases: 📍 Geospatial queries (ride-sharing, food delivery) ❤️ Matchmaking 📊 Observability dashboards 📝 Centralized logging (Elastic Stack: Elasticsearch, Kibana, Beats, Logstash) 🤖 Retrieval-Augmented Generation (RAG) Workflow: ...
This is a quick gist to demonstrate how you can run Elasticsearch securely with TLS on a public IP or domain. Sometimes, we need to spin up Elasticsearch for a development environment. In that case, you can follow these quick steps. Note - This gist is not recommended for production multinode cluster. As I only tested on single node cluster. If you have a multi-node cluster please follow the official guide. ...